2023. 5. 12. 17:59ㆍ논문 리뷰
1. Intro
대부분의 Pose Estimation Task에서는 객체에 대한 3D CAD 모델에 의존하며 이미 모델을 가지고 있다 하고 가정한다.
최근에는 Instance-level CAD 모델에 의존하지 않기 위해 category-level에서의 pose estimation 연구가 많이 진행되어 왔다. 같은 category 내의 서로다른 Instance들을 하나의 범주로 묶으면서 새로운 인스턴스를 일반화 할수 있게 되었지만 여전히 이는 많은 훈련 샘플을 요하고 또한 새로운 Instance가 기존의 category 샘플들에서 아주 다른 모양이나 크기를 가지게 되면 일반화 기능이 보장되지 않을 수 있다. 이러한 문제를 해결하기 위한 완전히 새로운 방식의 모델을 제안하는것이 OnPose이다. 객체의 sparse SfM 모델을 구축하기 위해 간단한 비디오 스캔만있으면 되며 CAD 모델이나 추가 네트워크 교training 없이 pose Estimation이 가능하다고 한다.

기존의 visual localization에서는 먼저 query image와 검색된 데이터 베이스 이미지간에 2D-2D 매칭을 수행하여 2D-3D correspondences를 생성하였는데 이는 느리기 때문에 real-time task에 맞지 않는다. 따라서 본 논문에서 제안하는 방식은 query image의 2D 좌표와 SfM Point cloud 상의 2D-3D 매칭을 직접적으로 하게 되면서 그 시간을 단축 시키는 방법을 제안한다. predict 할 시에 query image에서 2D local feature를 추출하고 SfM 모델의 포인트와 일치시켜 object pose를 PnP 알고리즘으로 계산할 수 있는 2D 좌표와 3D 좌표의 correspondences를 얻게 된다. 이를 가능하게 하는것은 GATs 라는 graph attention network를 사용하여 동일한 3D SfM 지점(즉 , 특징 트랙) 에 해당하는 2D 특징을 집계하여 3D 특징을 형성하는 방법이다. 이를 통해 추론시간을 하나의 frame을 처리하는데 단 58ms 에 처리할 수 있다고 저자는 말하고있다. 증강현실 AR TASK나 bin picking 과 같이 real-time에 적용되는 task에서 속도가 생명인데 instance의 특별한 훈련없이 58ms만에 추론이 가능하다면 정말 놀라운 일일 수 밖에 없다.
2.Preliminaries
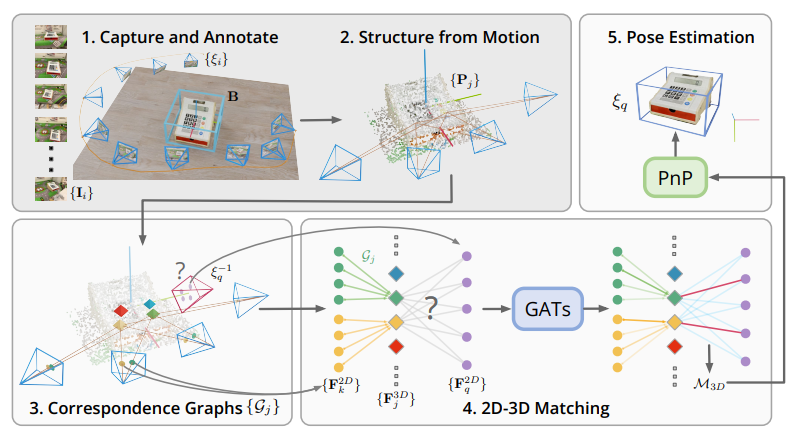
1.Capture and Annotate
1번단계에서는 여러방향의 각도에서 촬영한 비디오 스캔데이터의 RGB 프레임과 각 프레임에 해당하는 camera pose가 annotated된 3D 바운딩 박스 B와 함께 수집한다. B는 중심 위치, 치수 및 z축 주위의 회전에 의해 매개변수화된다.
2.Structure from Motion
Capture and Annotate가 완성되었으면 Structure from Motion(SfM) 을 사용해서 물체의 point cloud를 재구성한다. {Pj} 에서 j는 point index를 가르킨다. 재구성된 point cloud {Pj} 는 2D 키포인트와 descriptors의 집합에 매칭된다. 여기서 descriptors는 {F 2D k } ∈ R d 를 의미하며 k는 keypoint index 그리고 d descriptor의 차원을 말한다.
3. Corrspondence Graphs
Corrspondence Graphs {Gj} 는 SfM map 내에서 2D-3D correspondences를 표현한다. 주어진 다각도의 frame에서 2D 좌표들이 3D 점 하나로 유기적으로 연결되어있다.
4. 2D-3D Matching
2D descriptors 인 {F 2D k } 는 aggregration-attention layer와 함께 3D descriptors {F 3D j }로 통합된다. {F 3D j } 는
다시 query image {F 2D q }로 부터 예측할때 3D점으로 매칭된다.
5. Pose Estimation
Object의 Pose ξq가 PnP 알고리즘으로 해결하여 계산되어지게 되고 마침내 6D Pose Estimation을 할 수 있게 된다.
3.OnePose
Graph Attention Networks (GATs) for 2D-3D Matching
기본적으로 GAT는 Self-attention 메커니즘을 노드 Embedding과정에 적용한 신경망이다. Self-attention은 어떠한 입력을 이해하기 위해 같이 입력된 요소들 중에서 무엇을 중요하게 고려해야하는지 score로 나타내는 기법이다.
Attention Group 은 aggregation,self, cross attetntion layer의 집합으로 이루어 져있으며 아래의 수식이 하나의 attention group으로 설계되어있다. GATs는 아래의 attention group이 N개 만큼 stacking 되어 구성되어져 있다. 이러한 여려방식의 layer들로 구성하면서 {F 2D k }, {F 3D j }, {F 2D q } 는 서로 정보를 교환하면서 2D-3D 매칭을 위한 더욱 상세한 정보를 만들어내게 된다.

