2022. 12. 18. 16:29ㆍ논문 리뷰
NeRF 라는 정말 3D Representation 분야에서 혁신적인 개념이 등장했다.
2020년에 처음 출시되어 꾸준히 하루에 한개씩 논문이 나올만큼 3D Vision 분야에서 뜨거운 감자 같은 주제이니 반드시 알아 두어야 겠다고 생각하여 리뷰를 하고자 한다.
1. INTRODUCTION
기존에 3D Representation 방식에서 많이 사용되어지는 방법은 Discrete Representation 방식이며
주로 Voxel,PointCloud, Mesh등으로 많이 표현되었다.

NeRF 는 일반 2D 카메라를 이용해서 카메라로 인해 훼손된 빛에 의한 손실과 깊이정보를 복원하여 3D Representation을 하는 기술을 말한다. MLP에 학습시킬 입력으로써 카메라 시점 View Direction (θ, φ) , 카메라 파라미터 , voxel좌표(x,y,z) 그리고 2D RGB이미지가 주어 지며 50~100장정도 한 가지 Scene에 대하여 다양한 각도와 방향에서 촬영한 데이터를 학습시키고 모델은 각 point에 대한 Color (r, g, b)와 Density (σ ) 를 예측한다. 여기서 부피 밀도 σ(x)는 위치 x에 대해서 극소 입자로 끝나는 Ray의 미분 확률로 해석될 수 있다고하며, 즉 해당 위치 x에서 output volume을 얼만큼 차지하고 있는지에 대한 것을 말한다. volume density는 0~1사이 값을 가지며 density가 클수록 그 지점에서의 색상이 투명하지 않고 진하다는것을 의미하며 작을수록 연하다는것을 의미한다.
따라서 모델은 입력값 5D coordinate (x, y, z, θ, φ) 으로 부터 volume density 와 RGB color를 출력하도록하고 실제 이미지의 RGB값과 비교하여 Graident Descent 를 통하여 모델을 최적화 하는 방식으로 학습하게 된다. 결국 이러한 과정을 통해 원하고자 하는 것은 어떠한 새로운 방향에서 객체를 바라봤을때 2D 이미지로 촬영한 이미지를 3D Rendering을 최대한 잘 재현하고자 하는것이 목표이다.
2. Neural Radiance Field Scene Representation

구조를 파악하기전에 먼저 Ray라는 개념을 알아야한다. 논문에서는 ray를 r(t) = o + td 와 같은 수식으로 표현하고 있다. Ray는 실제 Voxel좌표계(x,y,z) 에서 물체를 찍은 카메라 방향으로 일직선으로 향하는 선을 의미한다. 학습을 위해 Ray 위의 랜덤한 Voxel들을 Sampling하여 학습에 사용하게 된다. 모든 좌표를 모두 학습에 사용하게 되면 비용적인 측면에서 효율이 떨어지기 때문에 적절하게 1차적으로 coarse하게 Sampling하고 2차적으로 σ가 높은곳을 위주로 더욱 많은 voxel을 Sampling해서 1차와2차 Sampling Fine Sampling하는 방식을 사용하여 모델의 Input으로 사용할 3D point들의 Sampling Set을 만들어낸다. 이렇게 생성한 Set을 각 Ray에 해당하는 2D View Direction과 함께 (x, y, z, θ, φ) 로 만들어 해당위치에서 바라본 객체의 RGB Color와 Density를 얻게된다. 논문에서는 다음과 같은 과정을 FΘ : (x, d) → (c, σ)로 정의하고 있다. 여기서 x는 (X,Y,Z)를 의미하고 d는 객체를 바라보는 방향(viewing direction)을 의미한다. 마지막으로 이렇게 예측된 color와 Density를 Classical Volume Rendering Technuques 라는 전통적 Rendering 방식으로 통해 하나의 Pixel의 값으로 축적 시켜주어 실제 이미지의 해당 Pixel RGB 값과 비교하여 Loss를 구하는 방식으로 학습을 한다.
모델의 전체 구조를 보면 다음과 같다.

Network는 간단한 MLP로 구성되어 있으며 8개의 Layer에서 Relu Activatoin 을 거치며 최종 Output으로
density와 rgb 값을 출력으로 얻게 되는 구조 이다. 여기서 r(x)로 표현되는 입력이 3D Voxel 좌표가 되는데 3차원 데이터로 그대로 넣어주는 것이 아닌 Positional Encoding을 거쳐 차원을 증가 시킨 60차원의 입력으로 넣어주게 된다. 이렇게 해주는 이유는 high frequency의 영역에서 정확도를 높이기 위해 이 과정을 거치게 되고 이는 position정보를 Aug 하는 역할을 함으로써 Data Augmentation 개념으로 이해하면 편하다. 입력으로 사용할 view direction (d) 값이 input에서 바로 활용되지 않고 8개의 layer를 거친후에야 input으로 들어간다. 왜냐하면 voxel 좌표는 color,density에 모두 영향을 끼치지만 view direction은 color에만 영향을 미치기 때문에 8개의 layer를 통해 density를 먼저 추출한 뒤에 view direction 과 함께 color값을 예측하는 형태로 이루어 진다. 네트워크 중간에 한번 더 60차원의 3d point를 더해주는 Skip Connection 을 취하고 있는데 이는 층이 깊어질수록 발생하는 Gradient Vanishing 문제를 해결하기 위하여 위와 같은 구조를 취하고 있다.
3. Classic Volume rendering
볼륨 정보를 가지고있는 object 로 부터 2D 이미지 컬러를 렌더하는것을 Volume rendering이라고 칭한다. 이때 2차원이미지에서의 컬러픽셀을 나타내는 수식이 다음과 같이 정의되어진다.


위 수식은 왼쪽 그림으로 설명이 가능하다.
먼저 ray에 대한 수식을 r(t) = o + td 로 표현한다고 하였다.
여기서 o=원점(view point지점) , d는 direction 을 말한다.
t는 또한 객체가 있을법한 곳의 가장 가까운곳을 tn 그리고 가장 먼곳을 tf로 표현해볼 수 있을것이다. 따라서 tn 과 tf 사이의 t점에서 volume density값과 color값 을 알고있다면 2d 이미지에서 rendering된 rgb 값을 알 수가 있게된다.
수식 내에서 T(t)는 Accumulated transmittance이며 투과율을 의미한다. 오른쪽 수식을 보면 tn 즉 view point에서 출발하여 객체가 있을법한 가장 가까운 지점 tn 부터 특정한 위치 t까지의 volume density값의 적분계산식을 확인할 수 있다. 결국 T(t)는 tn부터 t사이에 얼만큼 많은 장애물들이 가로막고 있는지에 대한 척도를 나타내는 값이라고 할 수 있겠다. 만약 t앞에 많은 불투명한 물체들이 놓여져있었다면 그 지점들에 대한 volume density(σ)의 값은 1에 가까울것이고 tn부터 t까지 그값들을 적분하였을때 그 값이 커지기 때문에 -exp 그래프에 따라서 T(t) 값은 낮아지게 되며 반대로 가로막는 물체가 적으면 T(t)값은 높아지게 된다. 즉 식을 해석해보면 t지점보다 앞부분의 density가 작고 t지점의 density가 클수록 t지점에서의 색상값에 곱해지는 Weight가 커지게 된다.
이제 모든 t에 대해서 값을 계산할 수 없기 때문에 지점을 Sampling 하여 사용하며

이와 같은 수식을

이러한 discrete한 식으로 변형하여 사용하게 된다.
4. Positional encoding
앞서 설명했듯이 Nerf에서는 입력으로 위치 정보를 더욱 늘여주는 Positional Encoding을 통한 입력을 넣어 주었다.
이는 더 고주파 영역의 표현을 더욱 자연스럽게 하기 위함이고 논문에서는

다음과 같이 Positional Encoding이 없을때 경계표현을 잘 하지 못하는 점을 강조한다.
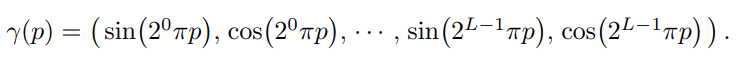
논문에 따르면 3D 좌표에 대해서는 L=10으로 더많은 정보를 늘여주었고 VIEW DIRECTION에 대해서는 L=4로 주어 3D 좌표보다는 비교적 적게 늘여주어 X,Y,Z는 총 60개 VIEW DIRECTION는 총 24개의 데이터를 생성하였다. 즉 3x10x (2L) = 60 이고 이때 view direction는 3차원 내 벡터로 표현되기 때문에 3차원x4x2L = 24 차원 으로 계산할 수 있다.
5. Hierarchical volume sampling
Sampling을 위하여 먼저 stratified sampling이라는 Sampling방식을 사용하여 Coarse한 방식으로 Nc개의 구간내에서
좌표를 뽑는다. 이렇게 Sampling 된 좌표를 가지고 1차적으로 C(r)을 계산하고 Coarse Network를 학습시킨다.
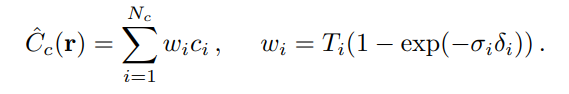
이렇게 해서 구한 Weight값(wi)을 Normalize 해서 ray를 따라 확률분포 (PDF)를 구하고 그후 Nf locations에 대해 Inverse transform sampling(CDF의 역변환을 통해 확률변수를 구하는 방식) 을 통해 Sampling하고 Nc+Nf sample을 사용하여 fine Network를 학습시키고 학습된 모델을 통해 최종 Cf(r)을 계산한다. 이렇게 함으로써 실제 객체가 존재할 영역에 있을법한 좌표들을 더 많이 사용하여 실제 객체를 렌더링에 사용하는 비중이 더 높아질 수 있다.