2023. 5. 12. 17:39ㆍ논문 리뷰
우리가 앞서 기존 Nerf 모델에서 이미지를 더욱 자세히 표현하게 해주는 기법인 Positional Encoding 기법에 대하여 다룬적이 있다. 기존의 Encoding 방식에서의 단점은 computational cost가 크기 때문에 속도가 엄청 느린 단점이 존재하였다. 이번에 소개할 논문은 어떤 Task에 국한 되지 않고 Nerf 이외에도 다양한 방법론에서 쓰일 수 있는 Multiresolution Hash Encoding 기법을 소개하며 동시에 빠르고 높은 퀄리티로 선명한 이미지를 얻을 수 있게하는 방법론을 제시한다.
1.INTRODUCTION

여러가지 분야에 적용될 수 있는 이번 Encoding 방식은 크게 4가지 방식에 적용될 수 있다고한다.
- GigaPixel image => SuperResoultion과 비슷한 것이며 초고해상도 이미지를 Rendering 하는 분야
- Neural signed distance functions => 3D cooridnates에 대해 주어진 Object Surface와의 거리값을 추정하고 object의 내/외부 위치를 파악하여 Reconstruction 하는 분야
- Neural radiance caching => TX의 신경망 가속 하드웨어(NVIDIA TensorCores)와 광선 추적 하드웨어(NVIDIA RTCores)를 결합하여 확산, 광택 또는 체적과 같은 모든 종류의 재료와 작동하는 완전 동적 전역 조명이 가능한 시스템을 만드는 것
- Neural Radiance Field => 시점이 알려진 2D 이미지로 부터 학습하여 새로운 관점에서 바라봤을때의 모습을 추정하여 3D Rendering 하는 분야.
2. BACKGROUND AND RELATED WORK

Encoding에 관련한 배경지식에 대하여 논문에서 소개하고 있다.
우리가 NeRF에서 사용하였던 Encoding 방식은 sin과 cos으로 이루어진 frequency encoding 기법을 사용하였다.

위 식은 [Vaswani et al. 2017] 에 나온 스칼라 포지션 𝑥 ∈ R 을 𝐿 ∈ N 개의 sin cos 함수로 이루어진 식으로 encoding하는 방식이다. 우리는 Nerf에서 위와 같은 Encoding 방식으로 더욱 선명한 이미지를 얻는것을 확인하였다.
근래 아주 활발히 연구되어지고 있는 encoding 기법은 Parametric Encoding 기법이다.
Parametric Encoding 기법이란?
=> 학습가능한 parameter들을 MLP가 아닌 grid와 같은 하나의 data 구조물에 넣어 parmeter를 업데이트 하는 방식이다.
예를 들어 Nerf와 같은 모델에서 3D Grid 를 사용하면 하나의 점에 대해서 3d grid 주변의 8개 외곽 점 8개만 update하면 나머지 weight들에 대해서는 업데이트를 할 필요가 없게 된다. 따라서 Computational cost가 적게 들어 Sota 모델에 유용하게 적용되고있는 Encoding 방식이라고 한다.하지만 Parametric Encoding기법의 같은 경우 Computational cost 측면에선 유리하지만 메모리 사용 측면에서 비효율적일 수 있다고 한다. 따라서 그를 해결하고자 나온 기법이 parse parametric encodings이다.
Sparse parametric encodings 기법이란?
=> 만약 특정 Task에서 중요도가 높은 부분을 알고있다면 octree 나 sparse grid를 사용하여 dense grid의 불필요한 부분을 제외하여 연산과 메모리양을 줄일 수 있다. 하지만 이도 NeRF같은 경우에는 중요도가 높은 표면 부분이 학습 도중에만 나오기 때문에 이를 활용할 수 없다.
3. MULTIRESOLUTION HASH ENCODING
MultiResolution Hash Encoding 기법은 위의 두가지 장점을 합쳐 놓은 Encoding 방식이라고 할 수 있다.
이미지를 Grid로 쪼갠 다음 각각의 점들을 Hashing하는 방식이다.
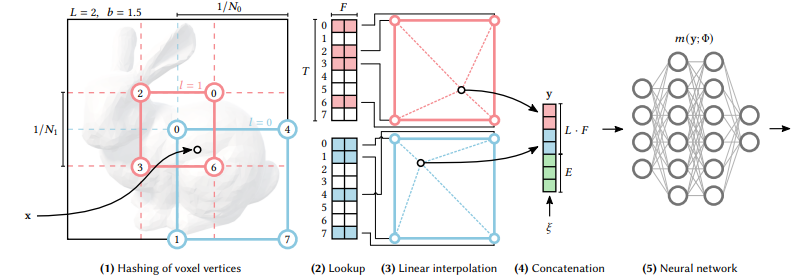
(1) 그림 같은경우 먼저 Nl resolution을 갖는 d 차원 grid를 정의한다. 각각의 Grid는 한 Level이며 차원수 d는 Task에 따라 달라진다.(Gigapixel : 2D, NeRF : 3D) 여기서 N의 값이 크면 클수록 즉 더 잘게 쪼개서 분석한다는 뜻이다.
(2) 각각의 Level을 T개수만큼의 F차원을가진 hash table에 mapping한다.
(3) Input coordinates가 voxel들로 mapping 된다.
(4) 만약 특정 level의 총 꼭지점 개수가 F차원 feature vector의 개수보다 작으면 1:1 mapping이 가능하지만 총 꼭지점 개수가 F차원 feature vector의 개수보다 크면 1:1 mapping을 할 수 없다. 이때는 Hash Function이라는 것을 적용하여 mapping하여 준다.

Hash Function
점의 개수가 Vector의 개수보다 많을때 결국엔 하나의 벡터에 여러 점들이 mapping 될 수 밖에 없는데 이러한 colliding 문제는 자연스럽게 해결되어질 수 있다. 가령 grid가 Coarser 한 경우 점과 벡터가 일대일 대응이므로 점 하나가 vector에 미치는 영향력이 크다. 반면에 grid가 Finer 한경우 점과 벡터가 n:1 대응이므로 점 하나가 vector에 미치는 영향이 줄어들게 된다. 따라서 자연스럽게 Coarse한 Grid에 따른 가중치가 부여되게 된다.
(5) D차원 linear Interpolation을 진행한다. Interpolation을 하지않으면 discrete 해지기 때문에 Interpolation을 통해 연속성을 보장한다.
(6) Interpolation 된 각 level의 vector들을 보조 input과 함께 Concatenation 한다. 보조 Input은 view direction , textures 등이 될 수 있다고 한다.
(7) MLP의 Input으로 Concatenation 된 vector를 받으며 MLP를 거쳐 원래 알고있던 X좌표의 정답값과 loss를 계산한 후 backpropagation을 통해 파라미터를 학습하게 된다.
4. EXPERIMENTS


기존 Encoding 방식에 비해 거의 몇십배 학습속도가 빨라졌으며 Quality는 비슷하게 유지하는것을 볼 수 있다. NeRF의 최대단점이 느린 학습속도였는데 획기적으로 이를 해결한 방식이라고 생각한다.