2021. 3. 23. 17:41ㆍPytorch
이번 게시물에서는 모델의 아키텍처를 많이 변경하지 않고도 Mixup, Label Smoothing, Knowledge Distillation, Cosine Decay, Zero Gamma, Model Tweaks와 같은 테크닉을 적절히 활용하여 ImageNet 데이터셋에 대하여 성능을 끌어 올릴 수 있는 방법에 대해서 게시하려 한다.
Label_smoothing
모델이 Ground Truth(GT)를 정확하게 예측하지 않아도 되게 만들어 주는 것.
Label_smoothing 이란 모델이 정확하지 않은 학습 데이터셋에 치중되는 경향을 막아 교정 및 정규화 효과를 가질 수 있는 방법이다. 즉 GT데이터가 잘 정제되어 있지 얺다면 오분류된 데이터가 있을 수 있어 모델이 이를 유하게 학습시키도록 하면 더 효과적이기 때문이다.
Label_smoothing을 적용하면 정답 레이블에 대해서만 100퍼의 확률을 부여하지 않는다.
텐서플로를 이용할 경우엔 BinaryCrossentropy & CategoricalCrossentropy 내에 자체적으로 적용이 되어있어 바로 사용하면 되지만 Pytorch를 이용할땐 따로 함수로 정의해주어야한다.

정의하는 코드는 다음과 같다.
참조
www.pyimagesearch.com/2019/12/30/label-smoothing-with-keras-tensorflow-and-deep-learning/
Label smoothing with Keras, TensorFlow, and Deep Learning - PyImageSearch
In this tutorial, you will learn two ways to implement label smoothing using Keras, TensorFlow, and Deep Learning.
www.pyimagesearch.com
Mixup
Mixup이란 학습을 진행할때 랜덤하게 두개의 샘플들을 뽑아서 믹싱을 거친 새로운 데이터(x ̃,y ̃)를 학습에 사용하는것이다.

정의 하는 코드는 다음과 같다.
이를 적용시켜보면 고양이와 강아지를 적절히 섞어서
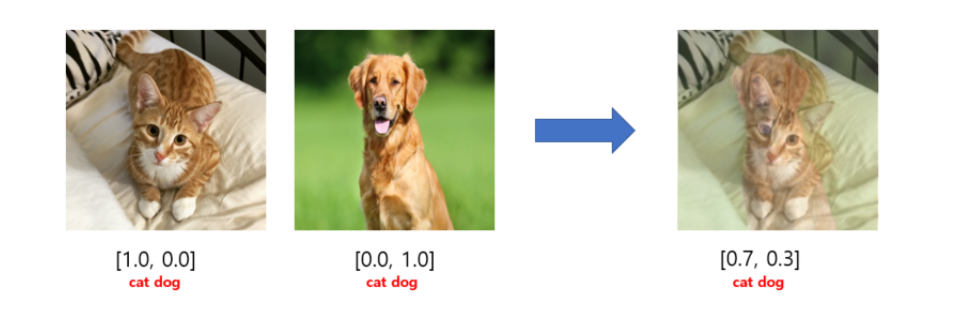
이와 같은 데이터를 만들어내고 이를 학습데이터에 사용한다.
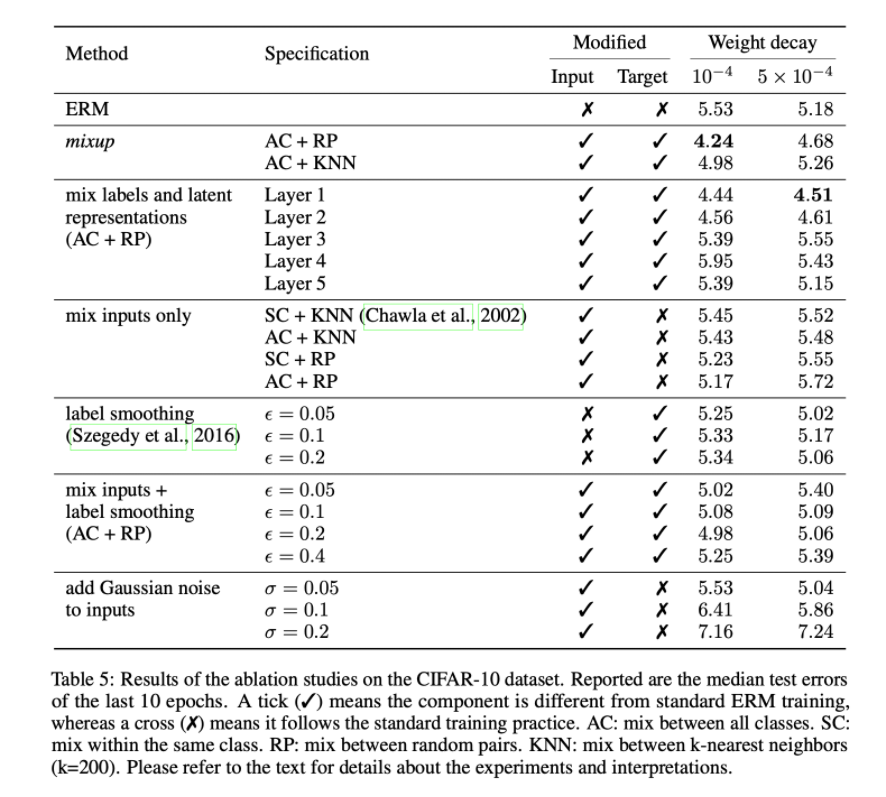
위 논문은 이를 적용하여 CIFAR-10 dataset에 적용을 하여 훈련시킨 결과를 나타낸다. weight_decay는 10^-4가 우수하다고 한다. 또한 AC+RP 가 가장높은 ACC를 보였다고 평가한다.
현재 진행하고 있는 lotte product classifiaction 모델 구성에 적용해보았는데 성능 평가는
훈련이 완료되는 대로 아래에 작성하겠다!
'Pytorch' 카테고리의 다른 글
| Detectron2 꼼꼼 정리 2탄 (0) | 2022.03.06 |
|---|---|
| Detectron2 꼼꼼 정리 (0) | 2022.03.04 |