2022. 3. 4. 17:37ㆍPytorch
오늘은 내가 개발 엔진으로 아주 잘 활용을 하고있는 Detectron2에 관해서 꼼꼼히 살펴보며 정리하는 포스팅을 해보려한다.
Detectron2란 먼저 FaceBook AI Research에서 개발한 차세대 오픈 소스 물체 감지 시스템이다. 한마디로 Vision과 관련한 Task들에서 Detectron2엔진을 사용해 개발을 하면 Detectron2 내부 engine 에서 학습이 진행되고 개발자는 모델 구축 이후에 입력과 출력만 어떻게 할 지 잘 정의하면 된다. 모델 zoo를 활용해서 Detectron2에서 제공하는것을 써도 되고 없는 모델을 사용하고 싶다면 모델구조와 configlation을 잘 정의하면 Detectron engine에서 학습할 수 있다.
먼저 Detectron2 설치를 해야한다. Detectron2는 Linux 환경에서 최적화 되어있음으로 최대한 Linux os에서 설치하여야하고 Window에서도 설치는 가능하지만 c++ 빌드 툴을 설치해서 돌려야한다. 하지만 Window 사용은 버그가 많으니 그냥 Linux환경을 추천한다. python version은 3.6이상 pytorch,torchvision은 1.8이상이면 된다.
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2설치를 했다면 Detectron2 폴더 내부를 살펴보면 아래와같은 트리로 되어있다.

'modeling' 폴더를 보면 Backbone 네트워크와 ROI_HEAD 네트워크 아키텍쳐가 담겨있다.
modeling/meta_arch/rcnn.py 에 보면 위와 같이 GeneralizedRCNN이 정의되어있는것을 확인할 수 있다.
Mask-RCNN에서는 기본적으로 Resnet + FPN backbone 네트워크와 RPN 네트워크와 ROI_Head 네트워크가 더해진 GeneralizedRCNN 이라고 불리는 구조를 사용하고 있고 위와 같은 모델구조를 가지고있다. 간략하게 몇가지 중요한 FPN과 RPN 네트워크 설명을 하려고한다.
FPN(Feature Pyramid Network)는 Multi scale feature map을 출력하여 작은 물체 부터 큰 물체까지 탐지하고자하는 크기의 Scale에 강해지기 위해 더해진 네트워크 이다. GeneralizedRCNN에서는 ResNet 기반으로 FPN이 설계되었고 bottom-up pathway, top-down pathway, lateral connections 이라는 세가지 과정을 거쳐서 최종적으로 Scale이 다른 p2,p3,p4,p5 의 네개의 Feature map이 출력되게 된다.
먼저 bottom-up pathway 과정에서는 CNN 레이어를 통해 2배씩 작아지는 Featuremap을 형성하게 된다. 이때 총 4개의 feature map을 추출하게되고 각각 원본이미지의 1/4,1/8,1/16,1/32 크기를 갖게 된다.
top-down pathway 과정에서는 1x1 conv 연산으로 output channel을 256으로 동일하게 만든다. 이때 c2~c5에서 위 feature map을 2배로 upsamapling하면 한칸 아래 1x1 conv로 256 채널로 맞춰준 featuremap 과 크기가 같아지는데 두개를 Element-wise addition 하고 3x3 conv연산을 최종적으로하여 다시 P2~P5까지의 featuremap을 생성한다. 이때 아래서 부터 과정을 진행하면 C1은 너무 큰 메모리를 가져서 Feature map으로 사용하지 않음으로 C2와 연산할 Featuremap이 없기때문에 C2는 그대로 1x1 conv로 256 channel을 맞춰주고 3x3 연산하여 P2를 얻게된다.
[(C5,C4)->P5 (C4,C3) ->P4 (C3,C2) ->P3 (C2) ->P2] 과정은 이와 같다. 이렇게 하는이유는 아래에 있는 고해상도 Featuremap의 특징을 한칸 위에 있는 저해상도 Featuremap에 전달하여 전달함으로써 더 작은 객체를 잘 탐지하기 위함이다.
이렇게 만들어진 P2~P5 Featuremap은 RPN(Resion Proposal Network) 네트워크에서 사용된다.
RPN Network는 우선 크게 RPN_Head와 anchor genrator 부분으로 나뉜다. rpn_head는 StandardRPNHead class로 정의되어있고 anchor_generator 는 DefaultAnchorGenerator로 정의되어있다.
우선 RPN_Head 인 StandardRPNHead 에서는 3가지 과정을 거친다.
1. conv2d (3 × 3, 256-> 256 channels)
2. objectness logits conv2d (1 × 1, 256-> 3 channels)
3. anchor_deltas conv2d (1 × 1, 256-> 3×4(12) channels)
objectness logits와 anchor_deltas 는각각
pred_objectness_logits (B, 3ch, Hi, Wi) : 객체 존재 확률 맵
pred_anchor_deltas (B, 3 × 4 ch, Hi, Wi) : 앵커에 대한 상대적 상자 모양
을 나타내며 여기서 B는 배치크기 Hi 및 Wi는 P2에서 P6의 Feature map 크기에 해당한다.
그다음 DefaultAnchorGenerator에 대해서 설명하겠다. Config를 살펴보면 다음과 같이 ASPECT_RATIOS와 SIZES가 정의되어있는걸 볼 수 있다.
먼저 P2에서는 위 그림과 같은 종횡비로 총 세가지 anchor box를 가지고 있고 각각 1:2,1:1,2:1의 비율을 가지고 있다.
P2에서 P5로 갈수록 이 엥커 크기가 2배씩 증가한다고 보면된다. 이제 이 앵커들이 어떻게 배치되는지 확인할 차례이다.
앵커는 P2~P5 의 각 grid cell 마다 표시되며 아래 예시와 같이 anchor box를 가지게된다. 아래 예제는 Stride가 64일때 P6의 Featuremap이다. 예를들어 P6의 크기가 (13,20) 이고 보폭이 64일때 다음과 같이 좌표 (3,5)에 Anchor center를 가지고 앵커를 그리게 되면 아래 모습과 같을 것이다. stride가 64기 때문에 Anchor center의 좌표는 (212,320)에 해당하고 파란색 사각형 크기가 512,512 이다. 이렇게 p6에 모든 그리드에 앵커가 배치가 되면 13x20x3 =780개의 앵커가 생성되고 총 255,780개의 앵커가 생성이되게 된다.
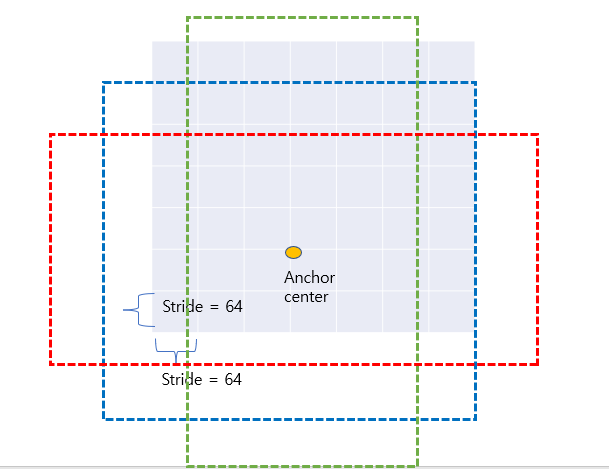
이제 이렇게 생성된 앵커박스를 Ground Truth Box와 연관 시켜야한다. 먼저 생성된 anchor box중에서 원본 이미지의 경계를 벗어나지 않는 anchor box를 추출하게된다. 이때 모든 Grid point에 대해서 Ground Truth Box와 관련해 foreground(1) 인지 background(0)인지 아니면 무시(-1)인지 샘플링을 하게된다. 여기서는 각 앵커박스와 ground truth box와의 IOU값을 계산해 0.7이넘으면 foreground 0.3이하면 background 0.3~0.7인 anchor box는 무시하게 되며 앵커를 선택하게된다.
이렇게 앵커를 선택하게되면 앵커 델타를 계산해야한다. Anchor Delta는 기본 Anchor의 크기와 위치를 조정하기 위한 값들이며 (deltaCenterY, deltaCenterX, deltaHeight, deltaWidth) 이런식으로 구성되어있다. 이들을 학습시켜나가며 실세 ground truth box의 정확한 위치를 찾아나가는 방식이다.
이제 앞서 objectness_logits와 anchor deltas를 구했으므로 이를 이용해 Loss를 계산하게 된다.
먼저 총 loss는 classification에 관한 loss와 box regression에 관한 loss가 더해져서 다음과 같은 형태를 취한다.
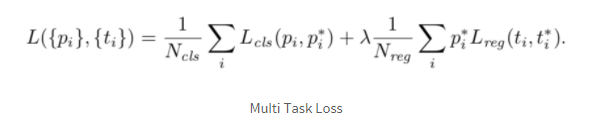
: index of an anchor
: predicted probability
: parameterized coordinates
: mini-batch size
: the number of anchor locations
: balancing parameter (default = 10)
: cross-entropy loss
: L1 smooth loss
* 가 달려있으면 groun-truth의 라벨을 의미한다. 확률에 있어서 = 1인 경우 positive sample이고, = 0인 경우 negative sample이다. 또한 여기서 mini-batch는 보통 하나의 이미지로 얻어진 앵커들 중에서 positive 128개+negative 128개 = 256개의 anchor로 구성된다. 이때 loss는 ground-truth 인 그리드 포인트에서만 계산되고 너무나도 많은 무시 혹은 배경 그리드 포인트는 무시되게 된다. 람다는 10으로 두 loss에 대하여 똑같은 가중치가 적용된다.
이제 마지막으로 Proposal selection 과정을 거침으로써 'proposal_boxes': 1,000개의 박스를 얻게 된다. 내용은 아래와 같다.
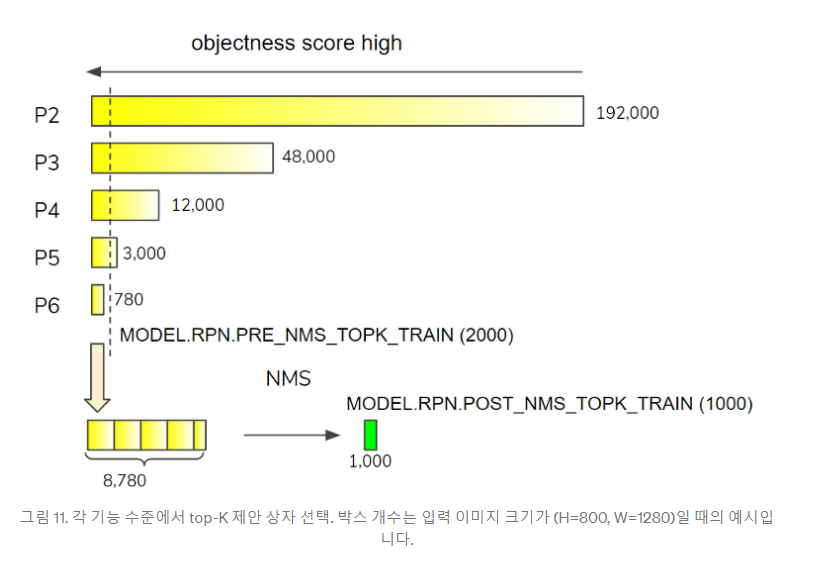
Detectron2 설명하려다가 Network에 대해서 기본적인 이해가 필요하니 장황하게 설명했는데 이어서 내용은 2탄에서 정리해보겠다.
# Refrence
https://herbwood.tistory.com/18
FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰
이번 포스팅에서는 FPN 논문(Feature Pyramid Networks for Object Detection)을 리뷰해보도록 하겠습니다. 이미지 내 존재하는 다양한 크기의 객체를 인식하는 것은 Object dection task의 핵심적인 문제입니다...
herbwood.tistory.com
https://medium.com/@hirotoschwert/digging-into-detectron-2-47b2e794fabd
Digging into Detectron 2
Part 1: Basic network architecture and repo structure
medium.com
https://ichi.pro/ko/detectron-2-salpyeobogi-4-bu-67157030933094
Detectron 2 살펴보기 — 4 부
안녕하세요. 컴퓨터 비전 연구원 인 Hiroto Honda입니다 ¹. [홈페이지] [twitter]이 기사에서는 리포지토리 구조, 네트워크 구축 및 훈련, 데이터 세트 처리 등 Detectron 2에 대해 배운 내용을 공유하고
ichi.pro
'Pytorch' 카테고리의 다른 글
| Detectron2 꼼꼼 정리 2탄 (0) | 2022.03.06 |
|---|---|
| Mixup and Label_smoothing (0) | 2021.03.23 |